Reproducibility & Data Science in R
Session 1
September 3, 2024
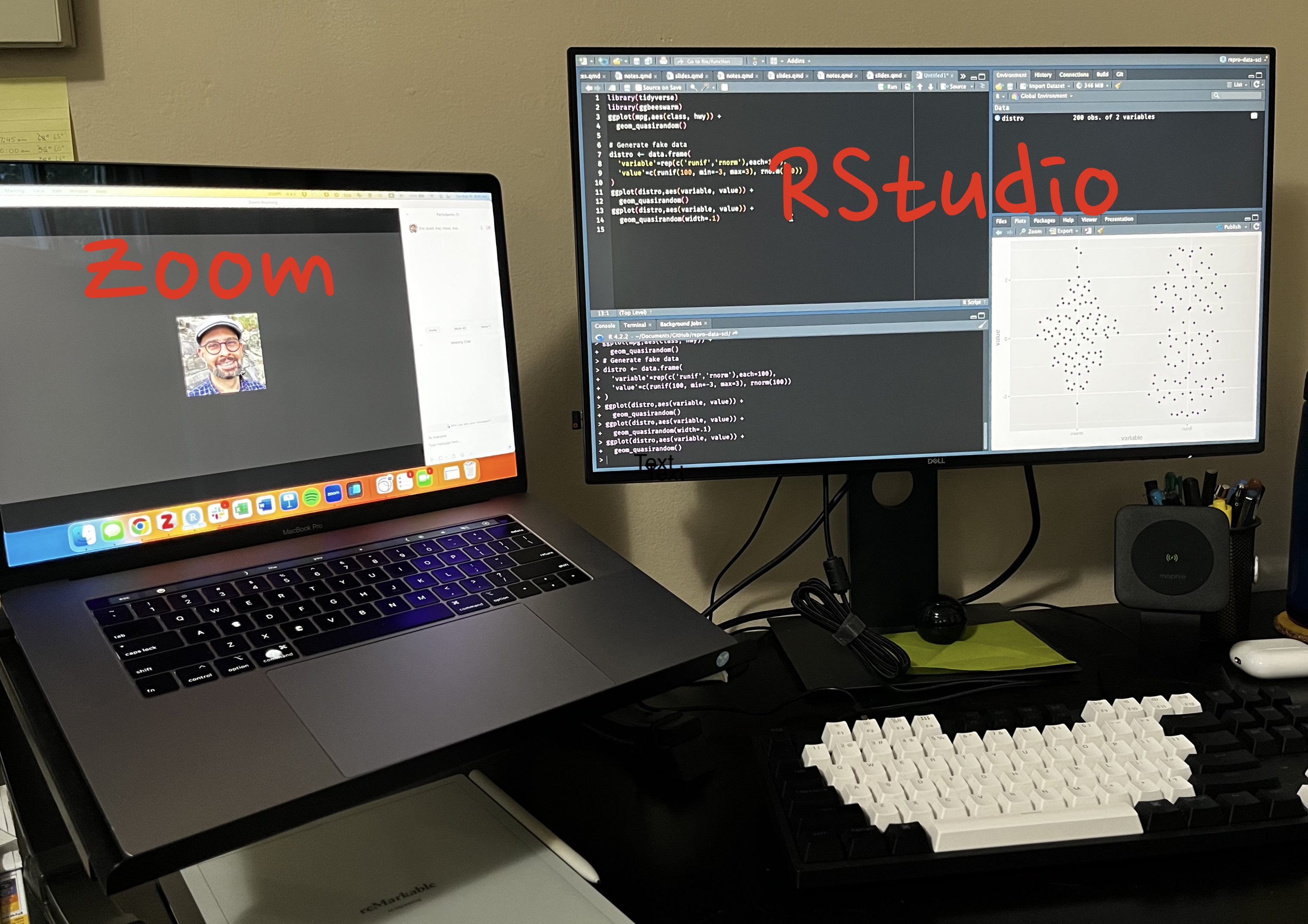
Screen Setup
- Dual monitors will be very helpful
- Virtual desktops (“Spaces” in macOS) also helpful
- Let us know if you do not have access to a second monitor
Basic compendium structure
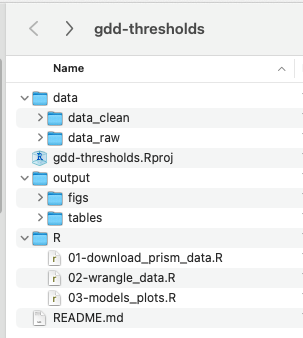
- Short machine and human readable name
- Separate folders for “raw” and “clean” data
gdd-thresholds.Rprojfile is created by RStudioR/folder contains all code to reproduce analysis. Could be namedscripts/or something else- R scripts are numbered with two digits so alphabetic sorting = numeric sorting
- README.md is a markdown (plain text) document (we’ll get to README’s later)
Settings for Success
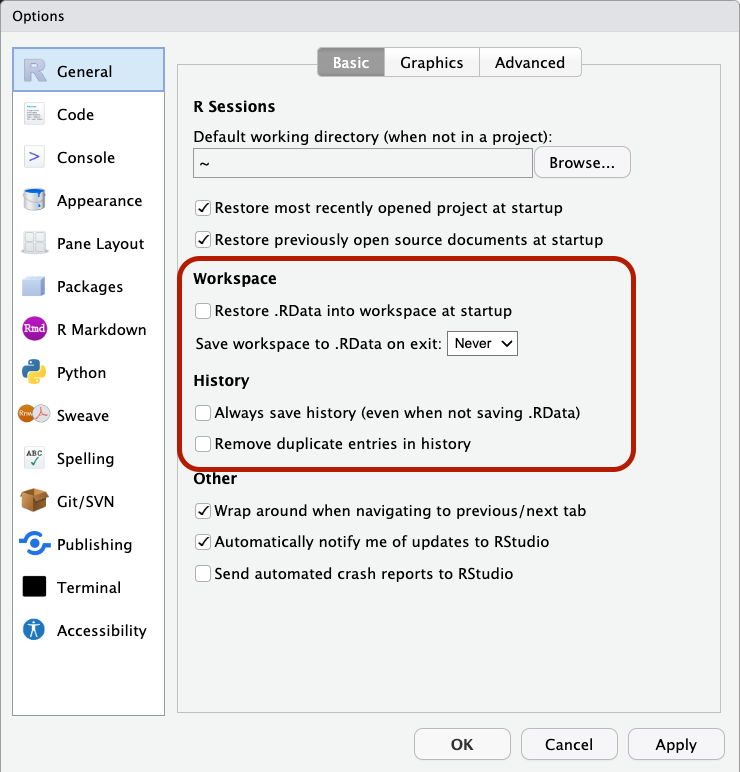
Fresh start ensures reproducibility
If your analysis relies on saving your environment in .RData, there are better solutions
References
![]()
Hicks, Michael Townsen, James Humphries, and Joe Slater. 2024. “ChatGPT Is Bullshit.” Ethics and Information Technology 26 (2): 38. https://doi.org/10.1007/s10676-024-09775-5.
Kabir, Samia, David N. Udo-Imeh, Bonan Kou, and Tianyi Zhang. 2024. “Is Stack Overflow Obsolete? An Empirical Study of the Characteristics of ChatGPT Answers to Stack Overflow Questions.” In, 117. CHI ’24. New York, NY, USA: Association for Computing Machinery. https://doi.org/10.1145/3613904.3642596.
Seibold, Heidi. 2024. 6 Steps Towards Reproducible Research. Zenodo. https://doi.org/10.5281/zenodo.12744715.
Wilson, Greg, Jennifer Bryan, Karen Cranston, Justin Kitzes, Lex Nederbragt, and Tracy K. Teal. 2017. “Good Enough Practices in Scientific Computing.” Edited by Francis Ouellette. PLoS Computational Biology 13 (6): e1005510. https://doi.org/10.1371/journal.pcbi.1005510.